![[EP -8] The Magic Behind Blockchain: ⇛ Delegated BFT 1.0 ⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c0f8dce67b3dc4cf3b9_6630c2243bba2e9140f92ed6_63d2c94b125a1b1db7fbf257_1_wbKwYxo-8KC6TOdnVtoReQ.png&w=3840&q=75)
Previously on Episode 7 of “The Magic Behind Blockchain”…
- we journeyed through the invention process of Practical BFTs showing how the classical Byzantine Fault Tolerance (BFT) protocol was made more efficient with the introduction of Practical BFTs.
- we went through the main phases of the pBFT protocol (Pre-prepare, Prepare and Commit) as well as View Changes and Garbage Collection. We also talked about Safety and Liveness.
- we derived 2 equations that showed that the asymptotic complexity for network communication / bandwidth and space usage are both O(n²) (quadratic). This was a significant reduction of the space complexity from O(nᵏ) (exponential) when it comes to classical BFTs.
- we ended the episode with some pros and cons of Practical BFTs
In today’s episode, we will dive into Delegated BFTs, answering questions like:
- What exactly are Delegated BFTs?
- What makes them different from the Classical and Practical BFTs?
- What are the improvements made in Delegated BFTs (in terms of time and space complexity) and what are the pros and cons?
QUICK OVERVIEW OF PRACTICAL BFTs
As we already established in the previous episode, Practical BFT is 3-phase protocol (Pre-prepare, Prepare and Commit) occurring amongst primary nodes, replicas (backup nodes) and clients. All this happens in eventual / partial synchrony (explained in episode 6).
The Pre-prepare phase is a one-to-all communication phase, thus the primary node multicasts to other nodes. At the end of this phase, basically the goal of each node is to say: “I can confirm myself that the sequence number and view of this request, therefore, I will store it in my log (update my state)”.
The other two phases (Prepare and Commit) are all-to-all communication resulting in the O(n²) complexity. The goal of the Prepare phase is for each node to say: “i have confirmation from 2f+1 people (including myself) that this request is in good order (right sequence number and view).”
The goal of the Commit phase is for each node to say: “I can confirm from 2f+1 people who have also all individually confirmed from 2f+1 people that this request is in good order (right sequence number and view).”
At the end of the 3 phases, all honest nodes can agree on the finality of the client’s request as well as its sequence amongst other client requests.
Usually what happens is that the system progresses in these 3-phase cycles with a reply at the end. At specific intervals, the 3-phase + reply cycle is interrupted by a view change. View changes determine a new primary node who then takes over and the cycle continues. This is done to maintain liveness and prevent the system from waiting too long when there is a faulty primary.
An important thing to note here is that when a node triggers a view change, it waits for say T seconds and then keeps doubling the waiting time if it has not received 2f + 1 (where f is number of faulty nodes) confirmations from other nodes of the view change. So it waits T, 2T, 3T, and so on. If you decided to program this, you can easily use the shift-left operator. So for example: if a node is to wait for 10seconds the first time, the next view change request waiting time (if no confirmation is received will be) 10 << 1 = 20secs, then 10 << 2 = 40secs, then 10 << 3 = 80secs, and so on.
The image below shows the lifecycle of Practical BFT. You can always catch up on the details in the previous episode.
This original protocol as developed by Barbara Liskov and Miguel Castro has gone through several modifications and variations such as in HyperLedger Fabric, Sawtooth, SBFT, Tindermint, Hotstuff. Most changes focus on more efficiency, rotating leadership (view change), etc.
HOW DELEGATED BFT WORKS
Delegated BFT (or dBFT) was created to solve some of the core issues in pBFT. Blockchains like NEO and Ontology Blockchain (ONT) popularised dBFT.
It should be noted that there are two versions of dBFT: version 1 and version 2. The original dBFT (version 1) resulted in the NEO hash fork in 2017 (explained later) which led to dBFT version 2 (the improved version) in 2019.
Please note that Delegated BFT is strictly a variant of the original Practical BFT. Therefore, everything we learnt in the previous episode applies.
VERSION 1 DELEGATED BFTs (ORIGINAL dBFT)
The first “strange” thing you will notice about dBFT (version 1) is the naming changes. In Delegated BFT, the primary node is known as the speaker, the replicas / backup nodes are known as delegates (or sometimes congressmen) and the clients are known as common nodes.
Secondly, in Practical BFT, clients submit atomic and independent requests (containing specific operation) for a unique timestamp (and sequence number + view), which are processed and published independently. Therefore, one request per consensus round (cycle).
In dBFT, consensus nodes have to group individual transactions / requests into batches, called blocks. This obviously increases the number of independent transactions finalised per consensus cycle. Instead of one request per consensus cycle, you now have multiple requests per cycle depending on the block size (number of requests in a block). NEO currently has block size of 100kilobytes which is able to process a maximum of 500 transactions per block.
Each execution of the dBFT protocol begins with the committee selection algorithm and leader election algorithm to form a consensus group (delegates) and to select a primary (speaker) from the group.
The speaker (primary node) is selected by the formula p = (h-v) mod N instead of p =v mod N as was in Practical BFT. Here h is the block height, v is the view number (a view is just a unique configuration of speaker and delegate nodes), and N is the total number of nodes in the network. So N is mathematically a real number. p is just the unique number of the primary node between 0 and N. Note that this equation could sometimes be p = (h +v) mod N.
A block height is just a specific location on the blockchain denoted by how many confirmed blocks precede the current block. Note that several 1000s of valid blocks may occur at the same block height. This may happen simply due to the different combinations of transactions in blocks. In order to guarantee that there is a unique block at each height, dBFT considers situations where a client may be faulty. This is not explored in pBFT
The delegates (or replicas) are required to vote for the received messages / blocks and maintain a global ordering / sequence of consensus decisions (blocks). Usually the delegates are selected from the clients (or common nodes) according to their reputation as defined by NEO. Clients also help to disseminate messages through the underlying peer-to-peer network. They provide various end-user services including payment, exchange, and smart contracts.
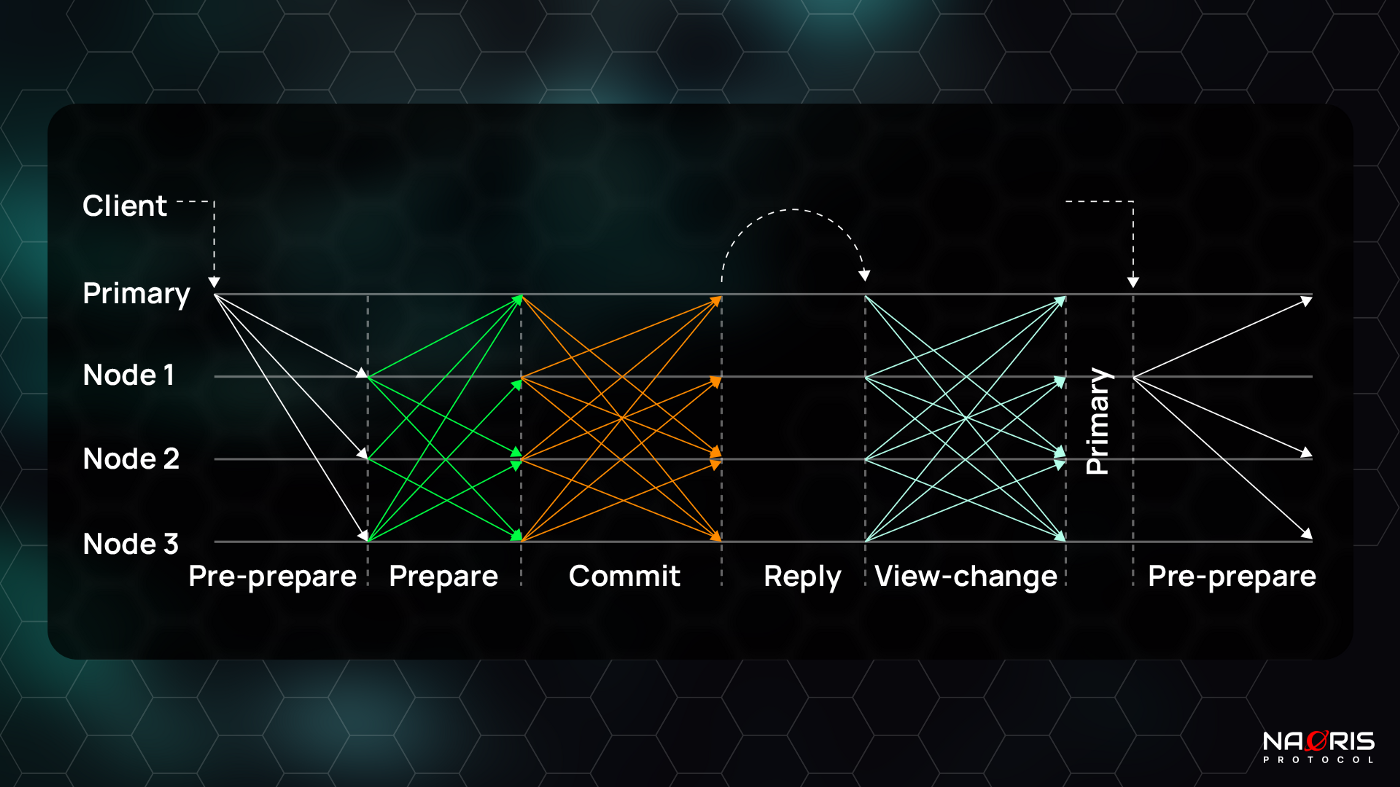
Original Delegated BFT has 2 phases instead of the regular 3 phases in Practical BFTs. There is the Prepare (sometimes called Prepare Request similar to Pre-prepare phase of pBFT) and Response (sometimes called Prepare Response similar to Prepare phase of pBFT). The replies stage of Delegated BFT is known as Publish (sometimes known as Commit but not the same as Commit phase of pBFT). So instead of Pre-prepare, Prepare, Commit and Reply (3 phases + reply) in pBFT we have Prepare, Response and Publish (2 phases + Publish / reply) in dBFT. The image below shows how the lifecycle works:

For simplicity and backwards-compatibility of understanding, I have represented the first phase of dBFT (Prepare Request) as Pre-prepare from pBFT. The second phase of dBFT (Response) has been represented as Prepare from pBFT for the same reasons. At this stage, the name changes here are purely cosmetic. Functionally as a consensus step, they are very similar.
If you compare the above 2 images, you should immediately see that dBFT seems much more simplified especially after removing the Commit phase (arrows in orange in the first diagram). But at what cost?
As usual in the Pre-prepare (or Prepare Request) phase, the chosen speaker (or primary) multicasts the message it received from the client <Pre-prepare, h, v, p, block,<Block> >p*. This primary-signed message contains the block height h, view v, primary id p, and the block content.
Every delegate node receiving this message from the primary checks the signature and validates the block making sure it is in the right view, at the right height and that the block and its transactions are well-ordered. Only then do they cast their vote for the block by way of creating and broadcasting a Prepare (or Prepare Response) message. After each node receives 2f + 1 Prepare Response messages, it is considered prepared and then replies are sent back to the client.
Fun fact: A group of 2f + 1 nodes, where f is the maximum number of faulty nodes required for safety of algorithm, has a special name. It is called a quorum.
Note that the safety assumption still remains f = n — 1 / 3. So the n = 3f + 1 rule from our classical and practical BFT remains in place.
Now let’s put the pieces together by looking at the dBFT algorithm step by step:
- Committee selection: The first step is to select the consensus committee. In a blockchain like NEO, a number of clients are selected and promoted to become replicas or delegates. This is done according to their reputation. So a sort of Proof of Reputation protocol precedes the process. The details of the reputation selection protocol is technically not part of the BFT algorithm so it is left out of this episode.
- Leader election: Next the speaker (or primary) is determined by the equation (h − v) mod N, based on the current block height h, current view v and the size N of the consensus group. As block height h increases, the committee leader rotates because the equation “usually” results in a different number between 0 and N each time.. This means every round will have a new primary!
- Pre-prepare (Prepare Request): The primary creates a block containing valid transactions collected from the network, and sends a signed pre-prepare message <Pre-prepare, h, v, p block, <block>, p*> to all replicas. p* means message is cryptographically signed by primary.
- Prepare (Prepare Response): After receiving the pre-prepare message, each replica i checks the correctness of the message, including the validity of signatures, the correctness of h, v, p, block and the contained transactions. If the received proposal is valid, then it broadcasts a signed prepare message <Prepare, h, v, p block, <block>, i*> to all replicas.
- Reply (Publish): After collecting 2f + 1 signed and validated PREPARE messages from a quorum, any replica i is convinced that consensus is reached, and executes the request and broadcasts its reply <Reply, h, v, m, i , <block>, i*>.
- View-change: When detecting a faulty primary or when a quorum is not available, the replica i sends a VIEW_CHANGE message <View_Change, h, v+1, p, i, block, <block>, i*> to other nodes. View-change is triggered when valid messages are received from a quorum.
CHANGELOG: In essence, the original Delegated BFT is equivalent to Practical BFT where multiple transactions are processed per block, voting algorithm and reputation is used to select primary and backups (so more flexibility and democracy here), commit phase is omitted and garbage collection and checkpoint protocols are also omitted. dBFT also uses digital signatures rather than Message Authentication Codes in pBFT.
dBFT STATES
As established in Practical BFT, dBFT consensus also uses State Machine Replication. It means that at any point in time, every node has a very clear and well-defined state(s). State transitions occur factoring in input from round to round and network messages. The following are the 10 recognised original dBFT states.
- Initial : this is the initial state of all machines. For coordination, all machines need to begin in the same state so that transitions result in a deterministic next state.
- Primary : a node is designated primary if it’s number p = (h — v) mod N or sometimes p = (h +v) mod N
- Backup : If a node is not primary, it is automatically a backup. This is a boolean inversion of primary state if primary is true.
- RequestSentOrReceived : If a node receives a valid signature from primary, this state is set to true. It is false otherwise. This was introduced in dBFT 2.0.
- ResponseSent : true if block header confirmation has been sent;
- CommitSent : true if block signature has been sent;
- BlockSent : true if block has been sent, false otherwise;
- ViewChanging : true if view change mechanism has been triggered, false otherwise;
- MoreThanFNodesCommittedOrLost : true in the case that more than f nodes are locked in the committed phase or considered to be lost;
- IsRecovering : true if a valid recovery payload was received and is being processed.
The diagram below shows all the state transitions that may occur.

In the image above, v is the view, C is the clock, h is the block height, N is the number of nodes in the blockchain network, i is the number any replica, T is the standard block time. In NEO this is 15 seconds. The exp() operator is just an exponent of 2. For example exp(10) means 2¹⁰ .
When the protocol starts, each replica / node is in an initial state with view set to 0 (v := 0) and clock reset (C := 0). If a replica’s number i = h + v mod N, then that replica earns the primary state. If not, that replica is automatically designated the backup state.
If a node is in a primary state, it two options depending on the time it spends on the clock C:
- It can either execute the SendPrepareRequest action (which is essentially the Pre-prepare phase). Thus it proposes a new block (of ordered transactions) after time T (15seconds). Here it goes into the RequestSentOrReceived state. Technically it just sent a request. A replica would receive it.
- Or the timer T can expire. Thus after the clock C hits exp(v + 1) seconds or 2ᵛ ⁺ ¹, a View Change is triggered and the replica’s clock is reset to 0 (C := 0). Here it enters the ViewChanging state. After ViewChanging state, the next state is back to initial with a new primary.
Similarly, a backup node can enter the RequestSentOrReceived state if it executes the OnPrepareRequestValidBlock action. Basically the Prepare phase where it determines that this is a valid block and therefore disseminates it. However, if the backup’s clock expires, thus exp(v + 1), without receiving any request from primary, it can also trigger a view change and enter the ViewChanging state. Note that this guarantees liveness (prevents infinite waiting for response) in case primary fails.
Note that sometimes even after a node has reached the RequestSentOrReceived state, a view change may be triggered by another node. If no view change has been triggered, nodes can enter the last stage. This is the Reply stage (or Commit). Remember that replies are sent only after 2f + 1 prepared messages are received. In other words the EnoughPreparations action is fulfilled. Once a node reaches this stage, it enters the CommitSent state.
Entering the CommitSent state guarantees that no view change occurs because the node has already committed to a specific block from the primary. It just refuses to provide a signature to another block at the same height. This is how you get one unique block per height. 2 valid blocks at the BlockSent state at the same height would mean a fork. Nodes will be split on which block is the next! Clients would have to choose the block with the most votes. This means one step further before you can consider block finality.
After f + 1 replies (dBFT commits), the block is considered final so the node reaches a BlockSent state.
To prevent forks, we have to impose a new condition to ensure correct Block finality. So let’s write a Math contract. Given n blocks in any blockchain, block height can be denoted by the set H = {0,1,2,3 …, n}. Given any member, h, which belongs to set H, there should NOT exist any two different blocks bᶦ and bʲ which exist at the same height, say n, at the same time interval t. More concisely:
∀ h ∈ H = {0, 1, 2, 3, …, n} ⇒ ; not exist bᶦ = bʲ in t; where t is time interval
EFFICIENCY, TIME AND SPACE COMPLEXITY
Fortunately we already analysed this in detail in the previous episode, so it should be easier here taking into account the variations in Delegated BFT.
In terms of network communication, 1 message request from Client, n -1 pre-prepare messages (or Prepare Request) from Primary node, n(n-1) prepare messages (or Response) in entire system, and n replies. This brings the total to 1 + (n-1) + n(n-1) + n. This becomes 1 + n -1 + n²- n + n
The worst-case network bandwidth complexity of the entire system is therefore simplified as n² + n which in big-O notation is O(n²). Comparatively that the complexity for Practical BFT was 2n². Note that although both have the same asymptotic complexity of O(n²), given n = 1000 nodes, Practical BFT would use 2million communication while Delegated BFT v1.0 would use (1000² + 1000) = 1001000communication. This is almost half of the communications used!
In terms of space complexity, let’s assume each node will have to spend x megabytes for storing any message / field. So (n * x)megabytes in total for views, another (n * x) megabytes for a pre-prepare message, (n² * x) megabytes for prepare messages, and finally (n * x) megabytes for replies.
Therefore, the worst-case space complexity is x*(n + n +n² +n). This simplifies to [(n² + 3n) * x] space consumed, thus, also O(n²). Comparing this to Practical DBFT, it is also about half the space requirement.
Another important part to consider is Transaction speed. How many transactions per second (TPS) can you get out of Delegated BFT?
We realised that, in this protocol, using 1 consensus committee and 1 primary node, we will be able to have about 500 transactions per block every 15seconds. This is about 500 / 15 = 33 TPS. But the structure of dBFT is very powerful because it allows you to parallelize the network!
What if you split the entire network into say 30 committees? Each of the 30 committees would produce 500 transactions every 15 seconds so about 500 * 30 = 15000 transactions every 15 seconds bringing the transaction speed 15000 / 15 = 1000TPS.
Through appropriate optimizations, NEO has mentioned that it could even reach 10,000TPS. With the above calculations, we can already mentally imagine how to attain that transaction speed.
SECURITY AND ATTACK VECTORS
The specific variations created by Delegated BFT may make certain attacks or security loopholes in the core algorithm more prominent. Here are 5 of the top attacks / loopholes possible:
- Fault Forking: Imagine that you own a backup node in a dBFT network. For a particular Block X containing some transactions, you go through all consensus phases till RequestSentOrReceived state. And you have received 2f + 1 prepared messages after the Response phase. Suddenly you lose internet connection. The other nodes detect some problems too and hence create a new block which goes all the way through to the BlockSent state (finalized). When your connection is restored, your node will now be halted because you now have a block that is not accepted by the majority of consensus nodes. Any node that tried to finalize your block will also be halted!
- Hash Forking: Our current protocol has a rare loophole. It is possible that due to View changing and other network conditions. A number of nodes (x) between f +1 and 2f + 1; where f + 1 > x < 2f + 1 could receive enough confirmations for Block X with hash H(X) while the other nodes receive enough confirmations for Block Y with different transaction so hash H(Y).
Because of the lack of a Commit phase which essentially gives you the other node’s perspective of the blocks closest to being finalized, 2 separate blocks may be reached. This would halt the entire blockchain network until manual consensus is achieved! All nodes would have to agree on Block X or Y. Something similar to this happened to NEO in 2017 except luckily less than f + 1 replicas updated their state with the forked block.
3. View Change Randomization (Modular Congruence): This is a rather mathematical attack than software attack. Whether you choose p = vmodN or (h-v)modN or (h+v)modN, you could have a situation where say p1 is current primary.
p2 = vmodn or p2 = h — v modn or p2 = h +v modn= p1. The modular operator is such that a number may repeat. 5mod3 = 2, 8mod3 =2, 11mod3 = 2, etc. These are all congruents. You can end up choosing the same faulty primary and hurting liveness. Embed failsafe unit tests in code to make sure that view change does not result in the same view changed faulty primary.
4. Rogue Primary Double Spending Attack: Assume a network of 4 nodes A, B, C and D. Let’s say A is Primary. So A creates <Pre-prepare> messages for two blocks X and Y with conflicting transaction maybe to spend one coin multiple times (double spending). The primary A sends block X to nodes B and C and then block Y to node D. 2f + 1 in this case is equal to 3. Since nodes will not be able to ever receive 2f + 1 prepare messages because they have different blocks, a consensus on either block X or Y can’t be reached so a view change is triggered. If honest view change selects Node D as primary, Node D will initiate Pre-prepare on Block Y. After consensus is achieved, Node A can then also send a Prepare message for Block X. Remember node B and C already tried to reached agreement on Block X so node A’s prepare messages finally helps them reach 2f + 1. Now you have 2 valid blocks. Consensus Safety is Broken. The entire network will likely shut down due to the fork!
5. Rogue Backup Attack: This is a variation of the Rogue Primary Double spend attack. Assume a network of 4 nodes A, B, C and D. Let’s say Node A is Primary selected by (h-v)modN. Node B is a byzantine node. The Primary Node A sends valid proposal <Pre-prepare> for Block X. The byzantine node B uses the following strategy: If Node B receives 2f + 1 = 3 Prepare requests for Block X, it acts honestly. However, if it receives only 2f = 2 Prepare requests for Block X, it abandons the protocol and does nothing. This will likely trigger a view change since consensus is not reached. If Block B is selected as primary, then it can send a conflicting transaction in a new Block Y. Once Block Y passes, it sends the final delayed prepared message to finalize Block X. Bam! Another fork!
CONCLUSION
In this episode we have seen that making a few variations on Practical BFT such as removing the Commit phase, Garbage collection and Checkpoint and introducing clear states as well as batching transactions into blocks yields a massive improvement in efficiency (network time and space complexity). This is Delegated BFT. However, sacrificing the Commit phase of Practical BFT also creates some algorithmic safety, security, and liveness issues.
In the next episode, we will delve into Delegated BFT version 2 and lay out how to solve these safety, security and liveness issues while attempting to maintain efficiency.
Catch you later!