![[EP -7] The Magic Behind Blockchain: ⇛ Practical BFT ⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c10d5854320e1d56c88_6630c2245d445045bf6920c2_64678e718c7e5892341ab828_ep-7-the-magic-behind-blockchain-practical-bft.jpeg&w=3840&q=75)
Previously on Episode 6 of “The Magic Behind Blockchain”…
- we understood the classical Byzantine Fault Tolerance (BFT) algorithm from both a network (P2P layer) perspective and cryptographic / consensus perspective.
- we talked about the FLP impossibility and the 3 cardinal misconceptions important for security.
- Finally we derived 2 equations that showed that the asymptotic complexity of network communication / bandwidth and space usage are O(n²) (quadratic) and O(nᵏ) (exponential) respectively when it comes to classical BFTs.
- we realised that although unlike Proof-of-Work type algorithms, classical BFTs avoid the problem of randomly / probabilistically selecting the participant initiating consensus, achieving classical BFT algorithms in the real world is impractical after about 20 nodes.
In today’s episode, our focus will be Practical BFTs (pBFTs).
- How do we achieve BFT in the real world?
- How do we make it more practical and efficient?
- In summary, how do we solve our network and space complexity issues and create a protocol that more efficiently utilises resources (space, time, network)?
THE TIMELINE OF EVENTS (The 1980–2000 BFT boom)
How inventions occur always amazed me. Usually, everything is normal until a particular decade or couple of decades when suddenly, every scientist becomes obsessed with a particular problem. Many iterations of solutions are created until eventually, the problem is cracked. It’s almost like the universe wants that discovery to be out around that specific timeline. Fascinating stuff!
For BFT, there were 2 long decades (1980–2000) where most prominent scientists in the field embarked on a race to achieve BFT in practice. This history is important because, we learn the iterations of the solution and the tiny improvements that were made on the great timeline! A great lesson if we want to improve upon the existing solutions.
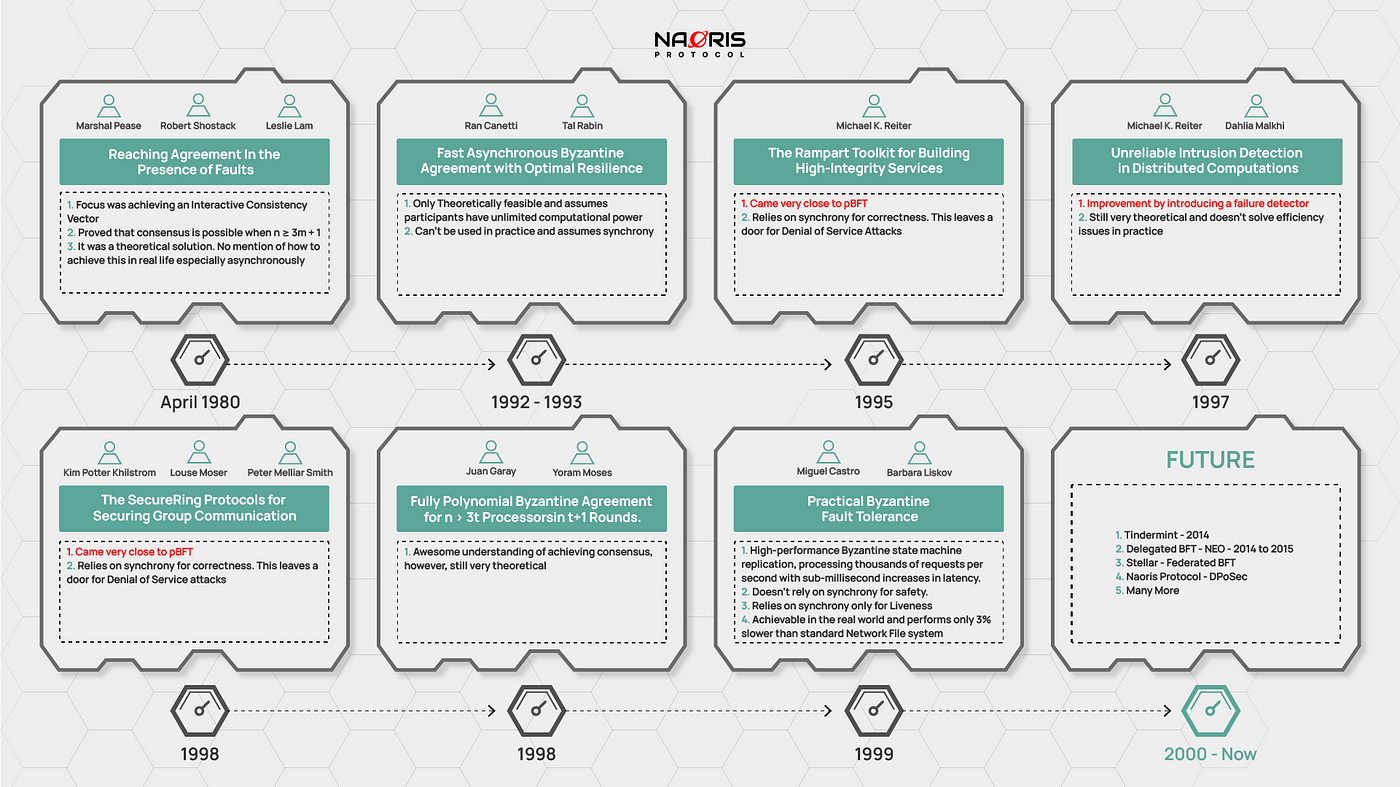
The image above shows some of the most notable papers and people that influenced the creation of pBFT in 1999 by Miguel Castro and Barbara Liskov. The entire race was to find a way to practically and efficiently achieve the classical BFT proposed in 1980 (by Marshal Pease, Robert Shostack and Leslie Lamport) in the real world. The two key problems prior pBFT solutions faced were within those 20 years were:
- Only Theoretically Feasible: Some of the solutions proposed were great, however, could only be achieved in theory. Any practical attempts were best case, inefficient and worst case wasteful and exorbitant.
- They assumed synchrony: Some solutions relied on known bounds of message / process delays. As we learnt in Episode 6, assuming synchrony especially for safety / correctness, is dangerous in the presence of malicious attacks. An attacker may compromise the safety of a service by delaying honest nodes or the communication between them until they are tagged as faulty (when the time elapses). They will then be excluded from the participants. Such a denial-of-service attack is generally easier than gaining control over a non-faulty node!
The introduction Practical BFT in 1999 had major improvements in speed. It is only 3% slower than the standard NFS daemon in the Digital Unix kernel during normal-case operation. It also has no synchrony assumptions for correctness / safety, therefore, not vulnerable to DDOS type attacks. Most importantly, Practical BFT is cost-efficient to achieve in the real world.
MENTAL SHIFT FROM Classical BFT TO Practical BFT
In this section, we really want to capture that “ahah” moment. The exact moment when the metaphorical lightbulbs were turned on in the heads of Miguel and Barbara (the pBFT inventors) during the creation of pBFT.
We know that classical BFTs proved that the BFT problem is only solvable for n ≥ 3m + 1; where m is the number of faulty / dishonest nodes. m is sometimes called t or f . We use m, f and t interchangeably in this series.
In other words, if you have 100 participants, a maximum of 33 participants should be faulty because m ≤ n -1 / 3. This means a little under one-third of the entire population is allowed to be faulty. If you have even 34 simultaneously dishonest nodes in a population of 100, you cannot achieve consensus using the classical BFT algorithm! The problem is unsolvable.
The classical BFT algorithm was looking at the equation from the perspective of the dishonest node requirements. For the first lightbulb to go on, the pBFT inventors must have looked at it from the perspective of the honest nodes. We know that for 100 participants, we need at least 67 nodes to be honest (100–33 = 67). So the honest must outweigh the dishonest by at least twice (+1). 67 = 2(33) + 1 = 2m + 1. Or if we use the notation of the pBFT inventors 2f + 1; where f is the number of faulty / dishonest nodes.
So you just turned n≥ 3m + 1 into 2f + 1 from the honest perspective. This means that, at a smaller scale, you will probably need less confirmations / less rounds. The first bulb is on! Note that this does not violate the original equation n ≥ 3m + 1. It is just another transformation!
Also consider this. What if out of these 100 participants where 33 are dishonest and 67 are honest, another 33 of the 67 honest face a legitimate network issue and can’t respond to requests? So out of 100 participants, 33 are traitors, another 33 are honest but have legitimate network issues. Meaning, effectively, there are only 100–33–33 =34 honest and working nodes. If you reduce this and ignore the 33 honest but unresponsive nodes, you practically have 33 traitors vs 34 honest nodes. In essence only f + 1 = 33 + 1 nodes are truthful in such a situation.
You can see that even when you double the faulty nodes, n — 2t is still greater that t. (100–2(33) = 34 > 33). In essence, you still have just one more honest person that turns the tide. This is a very resilient system.
This one more person is very important because it allows us to further reduce our security assumption of n ≥ 3m + 1 to f + 1 per individual. In essence, at a smaller scale, it will still be possible to have consensus even if the honest nodes outnumber the dishonest nodes just by 1 person. That is enough to spot an inconsistency!
Because mathematically if n — 2t > t, then n > 3t. So again we didn’t violate n≥ 3m + 1. This is a very powerful mathematical assertion because we have just understood that 3m+1, 2f+1 and f+1 can all be used to achieve consensus if the conditions are set right. The second lightbulb turns on!
The last lightbulb that must have turned on in the minds of the pBFT inventors was the simple fact that in classical BFT, each participant generates a unique secret in round 0 and initiates the consensus by sharing it. Confirming every individual secret for all n participants takes many rounds; hence the quadratic complexity in network communication and exponential space requirement.
However, what if instead of trying to validate the authenticity of every node’s secret, we start with just one random person sharing a message (secret), and all try to verify that? I mean, the point is to come to a single data point we all agree on. That data point does not necessarily need to come from everyone!
All participants can still quickly come to an agreement but in dramatically less rounds! Ahah! The last lightbulb turns on! We just have to find a way to randomly select the participant initiating the consensus. In essence, this will make the protocol only partially gossip-initiated consensus but it still works!
In summary, allowing a random node to initiate the creation of the Interactive Consistency Vector and reducing n ≥ 3m + 1 to 2f + 1 and f + 1 in some conditions, allows us to dramatically reduce the network and space complexity we faced in classical BFT without sacrificing safety and security.
THE PRACTICAL BFT ALGORITHM
Let’s start this section by noting a key point in Episode 6.
Although we introduced a picture showing asynchronous network communication in Episode 6, there was actually no talk of such a scheme in the original classical BFT paper in 1980 (Reaching agreement in the Presence of faults). There was literally not a single word like “async” in all 7 pages of the paper. The only reason why we showed the diagram was to give a feel of practical difficulty in achieving the consensus rounds even if we had the resources. That picture actually aligns more with Practical BFT and is shown in the detailed algorithm section.
The actual practical BFT algorithm is really quite simple. It has only 4 steps:
- A client (any device that wants a particular service) issues a request for a particular operation to be performed. This operation is issued to a temporary leader node of the network called a primary.
- The primary multicasts the requests to the other nodes (these nodes are called backups ). Multicast is used here instead of broadcast because not all other nodes may get the request sent out by the primary. This is called the pre-prepare phase.
- The replicas (backups and primary) multicast different confirmations of the request (prepare and commit phases). They finally execute the request and send replies back to the client.
- The client waits for f+1 replies from different backups / replicas with the same result. If there is no inconsistency (not even one), the results of the request are considered final. See how f+1 saves us here instead of 3f + 1? Because at the final stage you really just need 1 more honest person to outnumber the faulty (dishonest) nodes.
The entire process will look like this:

KEY ASSUMPTIONS OF PRACTICAL BFT ALGORITHM
At this point, we are all aware about the importance of assumptions to security and cryptanalysis. We have been speaking about exploiting assumptions since Episode 2.
The following are some of the main assumptions the designers of Practical BFT made:
- They assume an asynchronous distributed system where nodes are connected by a network (like the regular internet). The network may fail to deliver messages, delay, duplicate them, or deliver them out of order.
- Safety and Liveness are only guaranteed when there are at least n = 3f + 1 nodes, where f is the maximum number of simultaneously faulty nodes. In theory, you can go past 3f + 1 nodes, however, at this stage, the honest nodes already outnumber the dishonest / faulty nodes by more than 2 times. Therefore, there is no additional security advantage. In practice, there will be a degradation in efficiency since more nodes will be making transmissions for the algorithm. Note that a delay (t) is assumed for liveness. This synchrony assumption is required to circumvent the FLP Impossibility.
- The primary node initiating consensus must be randomly selected and not permanent. This randomness assumption is achieved via views. A view is just a configuration of n nodes where one is primary and the other are backups. For n replicas, there will be n views provided each replica is equally likely to be chosen as primary. This is usually achieved via simple formula like: i = v mod N (where N is total number of nodes). So let’s say we are in view 401 and there are 4 nodes, 401 mod 4 = 1, this means Node 1 is the leader.
- It assumes a State Machine Replication Model. This means all nodes / replicas must begin from the same initial state and they must be deterministic. Thus, given the same state and arguments, they must arrive at the same result.
- They assume byzantine failures with independent node failures. This is a very important assumption. For this assumption to be true when there are malicious attacks, various systems must have different implementations of service and OS. N-version programming same code different programmers, different implementations
- Channel security techniques such as signatures, message digests and MACs prevent spoofing and replay. All replicas know the other’s public keys.
- They assume a very strong adversary that can coordinate faulty nodes, delay communication, or delay correct nodes in order to cause the most damage to the replicated service. We do assume that the adversary cannot delay correct nodes indefinitely.
- Adversaries are computationally bound (polynomial time bound adversary). It is not able to break the cryptographic primitives used. Not a Quantum Computer. Thus produce a valid signature for an honest node, reverse a digest or find two messages with the same digest
- A client / node is honest if they follow the algorithm and no one can forge their signature so no masquerading
DETAILED ALGORITHM (HELLO WORLD PBFT)
To better understand the algorithm let’s walk through an example with four nodes A, B, C, and D. We assume:
- an external client Z that can interact with the network.
- The nodes are numbered from 1 to 4 respectively: So A= 1, B = 2, C = 3 and D = 4. So number of nodes n = 4, and f = n — 1/ 3 = 4–1 / 3 = 1. This system can only tolerate one faulty node.
- The algorithm proceeds through 3 phases: Pre-prepare, Prepare and commit.
- Each node / replica keeps a state which consists of a Message log containing all messages / requests replica has accepted and a number denoting the replica’s current view.
- This is the first time so view, v = 1. v mod n = 1 mod 4 = 1, therefore, each nodes stores in its state that the current view is 1 which means this configuration: node 1 (or node A) is the primary, and B,C and D are backups.
Client
- A client sends a message m which is formatted like this Z*<REQUEST, o, t, Z>. This means Z signs the message cryptographically. It contains the word REQUEST to show that this dataframe is a request, o is the operation to be performed (e.g. print hello world on all nodes), t is the timestamp of the request. Ensures uniqueness of request and that messages are ordered.
- The client expects (blocks and waits for) a reply in this format: ?*<REPLY, v, t, Z, i, r>. This means the reply is signed by one of the replicas. It contains the word REPLY to distinguish the dataframe. It also contains the current view number v, the timestamp, t, for the corresponding message. The client who sent the message, Z, i is the ID of the node / replica sending the response and r is the result.
- The client waits for f + 1 replies with the same timestamp t and response r. If the client receives these, the result r is accepted and the request and response are final.
- If the client does not receive replies soon enough, it broadcasts the request to all replicas. If the request has already been processed, the replicas simply re-send the reply; replicas have a log of all replies sent to each client. Otherwise, if the request is not already in the log and the replica is not the primary, it relays the request to the primary. If the primary does not multicast the request to the group, it will eventually be suspected to be faulty by enough replicas to cause a view change.
Pre-prepare Phase
1. Client sends a message m to the primary node A. The message looks like this Z*<REQUEST, o(hello_world), 4000, Z>. 4000 is the timestamp.
2. The primary node A looks at the timestamp and orders the request by assigning the request a sequence number. Eventually Node A multicasts the message <A*<PRE-PREPARE, v(1), n(1), H(m)>, m> to the other nodes B, C and D. v is the view (so view 1), n is the sequence number since this is the first and only request). H(m) is a hash of m say keccak256(m). m is also transmitted to ensure that receivers of the message can verify the integrity of the message via hashing and comparison.
3. Each of the backup nodes B, C and D receive the PRE-PREPARE message from the primary. Each of the backup nodes verifies the signature of the current primary on the message and the hash. They also check if indeed, their logs contain no pre-existing request with sequence number 1 in view 1. If the same request already exists, the current one is ignored. If the request is different but somehow has the same view number and sequence number, the primary must be acting dishonest so a view change is triggered. Nodes also check here that the sequence number exists within an agreed range to prevent primary from creating overflows (thus, between a low watermark h and high watermark H).
4. This phase is the most risky phase because it executes with the least consensus. It depends solely on the primary. However, in the following phases compensating controls are put in place to check the messages of the primary and ensure it acts honestly.
SUMMARY: The aim of this phase is for all backup nodes to say — “I have looked at this request m with sequence number n in view m and I can confirm for myself that it is in the right order”. 3 network messages in total are sent in this phase so (n -1) and O(n)
Prepare Phase
1. Client does nothing and is still waiting for a reply.
2. All backups make their confirmation of the pre-prepare message known to others. Node A, B, C and D create and multicast the following messages respectively to other nodes: A*<PREPARE, v(1), n(1), H(m),1>, B*<PREPARE, v(1), n(1), H(m),2>, C*<PREPARE, v(1), n(1), H(m), 3>, D*<PREPARE, v(1), n(1), H(m), 4>. Note that space is conserved here because the original message is no longer transmitted. Only the Hash H(m). Each node also adds their node ID to their messages.
3. When any node receives a prepare message, it verifies the signature on the message. It also ensures that the view number (1) of prepare message is the same as the current view of the receiving node. It also makes sure the sequence number is within the acceptable range. If all checks out, each node adds the prepare message to its log (state).
At this point, the individual states look like this:
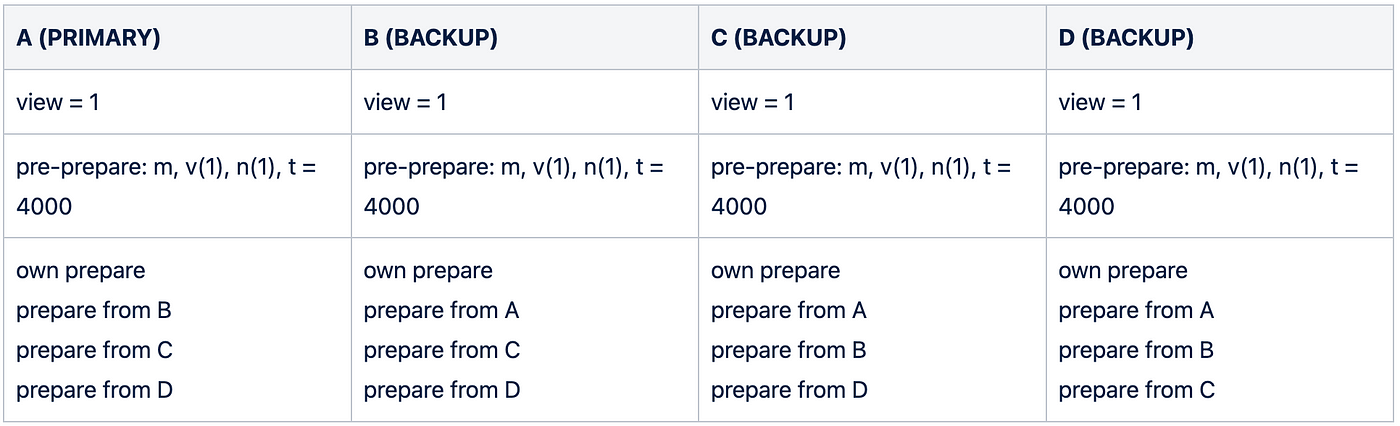
4. A replica considers a request as prepared if the prepared message’s hash matches a message in the pre-prepare phase (also in terms of view and sequence number) and that replica has received at least 2f other prepare messages from other replicas. In our example each node (A,B,C,D) only need two confirmatory prepare message to consider a message prepared since f = 1. This still satisfies our 2f + 1 principle if you consider the prepare message the replica logged on its own.
SUMMARY: The prepare phase together with the pre-prepare phase ensure that there is agreement about which request comes before the other within a view. In essence, each node is saying — “In addition to myself, I have a confirmation of 2f + 1 nodes saying that the message m in view v with sequence number 4000 is in good order”.
The proof that this works is trivial. If (m,v,n,node A) is considered prepared for a node, (m’,v,n, node B) cannot also be considered prepared by any honest node simply because m ≠ m’ and H(m) ≠ H(m’). Therefore you will never have f + 1 nodes to multicast this. That one honest node just won’t accept it.
Each node transmits n — 1 messages in this phase. So a total of n(n-1) messages are communicated in the network so O(n²)
Commit Phase
1. Each replica / node knows individually if they have received 2f + 1 replies and whether they consider the current request prepared or not. However, they need to multicast this to other nodes as well immediately prepared(m,v,n,node ID) becomes true. This is what happens in the commit phase.
2. Nodes A, B, C and D multicast the following commit messages A*<COMMIT, v(1), n(1),H(m),1>, B*<COMMIT, v(1), n(1),H(m),2>, C*<COMMIT, v(1), n(1),H(m),3>, D*<COMMIT, v(1), n(1),H(m),4>
3. When any replica receives a Commit message, it checks that it is properly signed and that the view, number and sequence number are in order. Then it commits it in its log.
4. There is a distinction between committed_local and committed. (m,v,n, node i) is considered locally committed if node i has considered the request prepared, thus, and prepared(m,v,n,i) is true and has also accepted 2f + 1 commits (possibly including its own). Any node can execute the hello_world request immediately it has achieved commit_local. On the other hand, a message is considered committed if and only if prepared(m,v,n,i) is true for ALL nodes (i) in some set of f + 1 honest replicas / nodes.
5. After achieving committed_local, the node sends a reply to the client Z with the result of the request. A, B, C and D send<REPLY, v(1), t(4000), Z, i, r(successful Hello_world)> where i is 1,2,3 or 4 depending on the node ID of the node sending the reply.
After the Client gets f + 1 replies (or at least 2 replies) with the same timestamp and result, it can consider the request executed and final.
At the end of the Commit phase, the state looks like this:
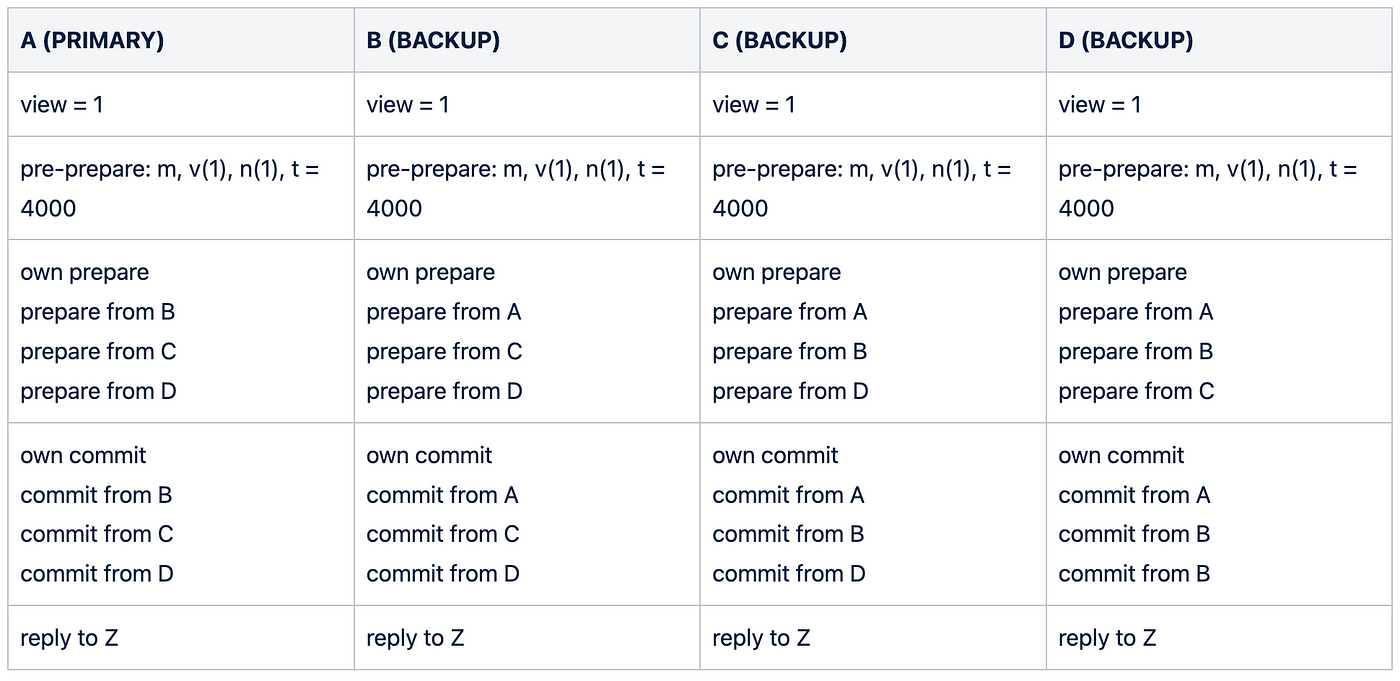
SUMMARY: If committed_local(m,v,n,i) is true for some honest node i, then committed(m,v,n,i) is also true. Together with the view change protocol, this ensures that replicas agree on the order of the requests (sequence numbers) that commit locally even if they commit in different view at each node. It also guarantees that any local commit will also commit at f + 1 nodes.
n(n-1) transmissions are made in total for commit phase so O(n²) and n transmissions for replies so O(n).
In essence each node is saying: “I can confirm from 2f + 1 people who have also all individually confirmed that 2f +1 people agree on the request (sequence number and view number)”
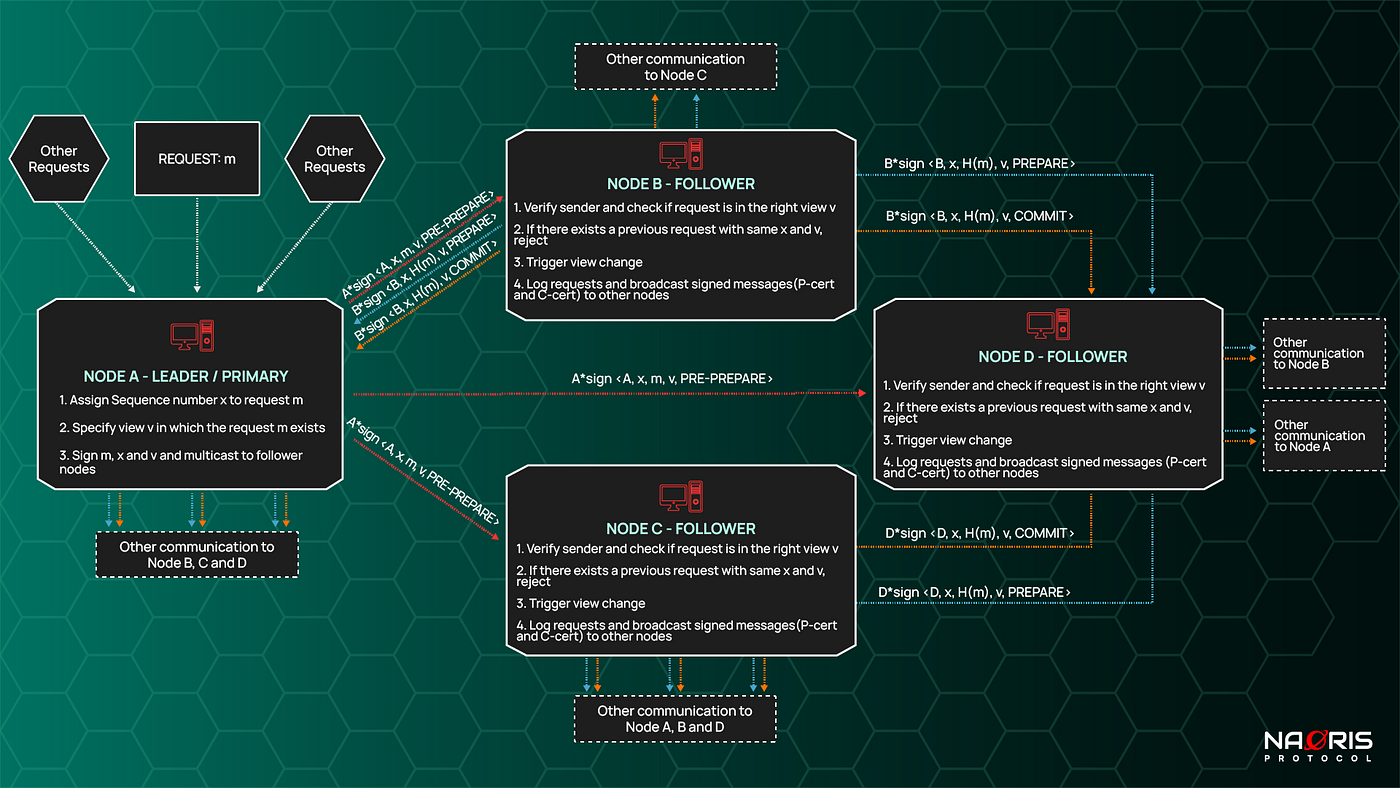
The figures below shows how these requests occur at the network level (Node0 = A, Node1 =B, Node2 = C and Node3 =D). Even assuming Node 3(D) has a byzantine fault and is not sending anything, request finality / consensus can still be achieved by pre-prepare, prepare and commit phases. Client still gets at least f + 1 (or in this case 2) replies.
Garbage Collection
We don’t need to keep all messages forever! Replicas can discard messages after they know that f + 1 honest (non-faulty) nodes have executed it. This check needs to be done to ensure safety. Sometimes some nodes may miss messages and may need to be brought up to speed. Therefore we can decide that after every say 100 requests, we will generate a proof of all the past completed transactions. This is called a checkpoint. Each node will simply send i*<CHECKPOINT, n, H(m),i>. This means Node i signs the message, i is the Node ID, n is the sequence number of the last executed request which is reflected in the state. H(m) is a hash (digest) of the state at that point. This proof of Checkpoint correctness can go through the consensus rounds again. So each node must receive 2f + 1 CHECKPOINT messages with same n and H(m) before it is accepted as a valid checkpoint. Nodes missing some message receive a transfer of ALL or part of the state.
VIEW CHANGE AND LIVENESS
What if at some point, a chosen primary node decides to abandon the protocol? Does the whole protocol come to a standstill? The simple answer is NO. To ensure that every request receives a reply (ensure liveness), we use view changes.
When any backup node gets a valid request directly from a Client and realizes it has not executed it, it forwards it to the primary node. Usually backup nodes start a timer when they receive a request (and they don’t already have a running timer). The timer is only stopped when it is no longer waiting. After the timer runs for a while, if there is no pre-prepare message from the primary, the backup node does not wait indefinitely. It triggers a view change to move the current state from v to v + 1. So in our case view (v)was 1. The backup makes the following request i*<VIEW_CHANGE, v+1, n, C, P, i>. i is the Node ID (i* is node signature), v + 1 is next view. So our current view is 1, so next view is 2 which choses Node B as primary. n is the sequence number of the last stable checkpoint known to Node i. C is list of 2f+1 valid checkpoint messages proving the last stable checkpoint s. P is a set of P* for each request prepared at Node i with the sequence number greater than n. P* contains valid pre-prepare messages (without the corresponding client message) and 2f valid matching prepare messages.
When the new primary of view v + 1 receives 2f valid VIEW_CHANGE messages, it broadcasts a specific NEW_VIEW message following the right correctness steps. More details of this can be seen here.
Note that to achieve liveness, 3 things must be followed:
- A backup node that broadcasts a VIEW_CHANGE request must wait (start a timer for T seconds) for 2f + 1 similar VIEW_CHANGE messages for the same view v + 1. If the timer expires before 2f + 1 similar messages are received, the backup starts another round of VIEW_CHANGE request for v + 2. This time the backup waits for 2T seconds. This continues to v + 3 and waiting 3T, and so on till 2f + 1 replies are achieved. The backup always chooses and executes the next view change with the lowest number (Thus, v +1 is preferred over v + 2 if 2f + 1 responses are received for both new views). This is done to prevent a node from sending too many view changes.
- If at any point, a replica receives a set of f + 1 view changes for a view greater than its current view, it means something is happening. And even though this replica did not initiate the VIEW change itself, it must join the process and also send a VIEW_CHANGE request for the lower view number above its current view. This is done even if its timer has not expired!
- f + 1 is very powerful, because it signifies that consensus of 2f + 1 is very close to being achieved. Therefore a VIEW_CHANGE cannot happen until at least f + 1 VIEW requests are sent by different backup nodes. This prevents a faulty backup node from randomly triggering a view change.
As you can see, view change will not always occur in the first round for v + 1. Most times it could take up to v + 3 (3 rounds of view change communications) for a new view to be executed (even if the next view is v+1). This bring view change to O(n³) in worst-case scenario.
It’s important to note that, in most implementations, View Change also appears at the start of each new request, which means it’s possible that Node 0 is chosen as the primary node on transaction 1, while Node 1 takes over as the primary node on transaction 2. This is done to ensure equitable reward distribution and democracy / fairness of choosing primary node.
The image below shows how view changes occur.

TIME AND SPACE COMPLEXITY
In a scenario where every node is able to transmit without fault, we can calculate network bandwidth complexity as follows:
1 message request from Client, n -1 pre-prepare messages from Primary node, n(n-1) prepare messages in entire system, n(n-1) commit messages and n replies. This brings the total to 1 + (n-1) + n(n-1) + n(n-1) + n. This becomes 1 + n -1 + n²- n + n²- n + n.
The worst-case network bandwidth complexity of the entire system is therefore simplified as 2n² which in big-O notation is O(n²). This is the same complexity as classical BFT, however, remember that for 1000 nodes classical BFT uses 333,666,000 communications while Practical BFTs will use worst-case 2(1000²) = 2million communications! Same big-O notation but massive difference!
In terms of space complexity, looking at the final state table above, let’s assume each node will have to spend x megabytes for storing any message / field. So (n * x)megabytes in total for views, another (n * x) megabytes for a pre-prepare message, (n² * x) megabytes for prepare messages, (n² * x) megabytes for commit messages and finally (n * x) megabytes for replies.
Therefore, the worst-case space complexity is x*(n + n +n² + n²+n). This simplifies to [(2n² + 3n) * x] space consumed, thus, also O(n²). In practical terms, if you had a 1000 nodes and even assumed that x is 1megabyte which is very generous, 2(1000²) + 3(1000) * 1 = 2003000megabytes. This is about 2 terrabytes consumed across 1000 nodes! This is so cheap. 2terrabytes per request is less than 100dollars. Compare this to 236petabytes per consensus in a 30-node classical BFT network.
CONCLUSION
In this episode:
- We understood the Practical BFT protocol and how it dramatically improves upon the network time and space complexity requirements of practical BFT by using 2f + 1 and f + 1. This solves a scalability issue and asynchronous issues while maintaining safety.
- Practical BFT is also able to provide transaction finality without the need for confirmations like in Proof-of-Work type consensus models. (e.g. Bitcoin). At this same time pBFT is much more energy efficient.
- We understood how to maintain liveness of the protocol via view changes.
- We also saw some optimizations of the algorithm using Garbage collection and checkpoints.
However, it is not all rainbows and unicorns with Practical BFTs. There are some crucial cons to consider.
- O(n²) network communications is still very inefficient. Therefore pBFT consensus still works best with small consensus group sizes. View changes could even cause the network complexity to be O(n³)
- Using MACs (Message Authentication Codes)for message authenticity is inefficient considering the amount of network communication needed. MACs can also make it difficult to prove message authenticity to third parties. One could use digital signatures and multisig here, however, maintaining cryptographic security while overcoming the communication limitation is a tough balance.
- No fault-tolerant privacy is offered. Nodes may leak information to one another. We can look towards secret sharing schemes and ZKPs, and many other cryptographic private computation schemes.
- Lastly pBFT is also susceptible to Sybil attacks. A situation where a single party impersonates several nodes in an attempt to circumvent the algorithm. This attack is less practical in large scale pBFT systems, however, large scale pBFT systems are also inefficient due to the problems above.
In the next episode, we will discuss Delegated BFT and how to solve some of the issues affecting pBFT. Catch you later!