![[EP -6] The Magic Behind Blockchain: ⇛ Byzantine Fault Tolerance ⇚](/_next/image?url=https%3A%2F%2Fuploads-ssl.webflow.com%2F660e449a26dad71301a18f76%2F66310c0f5d307ed181dd57f8_6630c2245d8e3849264f1c1d_64678df0b1bc32557e59f3fb_ep-6-the-magic-behind-blockchain-byzantine-fault-tolerance.jpeg&w=3840&q=75)
reviously on Episode 5 of “The Magic Behind Blockchain”…
- we went through the 4 general categories of Consensus solutions (Economic Cost-Based , Capacity Consuming, Gossip-based and Hybrid protocols) and 2 types (Participant initiated vs Gossip-initiated)
- we summarised the knowledge needed for the beginner section (see Episode 1 to Episode 5).
This sets the tone perfectly to start tackling some intermediate topics.
Today, the entire episode will be focused on the classical Byzantine Fault Tolerance (BFT) consensus algorithm. We single out this algorithm from the 80+ protocols we looked at because it offers very secure consensus and could be highly performant if developed right.
COMPUTER FAILURES
Computers don’t always function as we would want. Oftentimes, they fail in different ways. However, in order to consistently revive / recover failed machines or exclude them when they are in a network, we need to understand how they fail.
There are many types of failures:
- Crash failures — irreversible halting of the system / process
- Omission failures — message is lost in transit due to transit malfunction, buffer overflow, collision at MAC layer, receiver out range, etc
- Transient failures — arbitrary / irregular changes in environment / global state. E.g. power surge, lightning ,radio frequency interference, etc.
- Security failures — security vulnerabilities leading to a failure
- Temporal failures — correct system results but too late to be useful. The inability to meet availability deadlines especially in real time systems.
- Environmental Perturbations — In most systems, correctness of services depends on the environment, therefore if the environment changes, a correct system can rapidly become incorrect. Some example are systems that use: time of day, assume a specific user demand, network topology, etc.
- Byzantine Failures — explained in detail in following sections
The simplest type of failure is that the node crashed. This is usually called a crash failure or a fail-stop. This is very easy for monitoring systems to detect and take appropriate action especially in a synchronous environment. You can just set a timeout. If the system does not respond in time t, take action X.
Of all the types of failures, Byzantine failures are the most difficult to deal with. In this write-up, we are not just singling it out because it is the most difficult. In fact, if you want to create consensus in a computer network where there are only point-to-point connections (peer-to-peer network), Byzantine failures are simply unavoidable.
BYZANTINE FAILURE
So what is a Byzantine failure? A Byzantine failure is simply a failure caused by a Byzantine fault.
A Byzantine fault is a fault caused by a system (computer in a network) exhibiting a lukewarm attitude. In technical terms, this node presents different symptoms to different observers. This makes it extremely difficult to diagnose this fault, thus, determine whether the node is alive or dead, honest or dishonest, facing network challenges or not. There is just a lot of inconsistency.
Funny enough, Byzantine faults were first modelled after a very similar problem we discussed in My First Consensus Algorithm — Bread & Cake Blockchain in Episode 2. However, in 1978, this problem was formalised by Robert Shostack after an old war story — The Byzantine General’s problem as we discussed in Episode 3.
BYZANTINE FAULT TOLERANCE (BFT)
Whenever we develop a system in such a way that it is resistant to Byzantine failures, we call the phenomenon Byzantine Fault Tolerance. In order to avoid ambiguity and understand the problem better, let’s model it in formal mathematics. This is like writing a precisely-worded legal contract from what we have already understood. So here it goes …
Given a set S which contains n components (|S| = n) such that S has all members of type Cᵢ and S = {C₁, C₂, C₃, … Cₙ }. We assume:
- t of the members present a byzantine fault, belong to set T = {t₁, t₂, … tₙ}. T for traitors.
- h members do NOT present a Byzantine fault (honest) and h = n — t where all h and t are of type Ci and belong to set S. H = {h₁, h₂,… hₙ}. H for honest.
- All elements of set S can communicate only via point to point communication (two-party messages) where Ci communicates with Cj (another member of set S)
- Sender is always identifiable by receiver and communication channel is fail-safe with negligible delay
Whenever any component, Ci, broadcasts a value x, the other components in Set S are allowed to discuss / gossip among themselves to verify the authenticity of x. And finally output a common decision value y.
The system is said to resist Byzantine faults if all the following conditions apply:
- If Ci is honest, all other components of set S agree on the same / common decision value y = x (mutual agreement)
- In any other exception to 1 above, all other components of set S still agree on the same / common decision value y (not the same as x but still agreed-on by all components)
- Members of set T (those presenting byzantine fault) are allowed to collude in order to corrupt common decision value y
NOTE: A consistent lie is not caught as a lie. It is indistinguishable from the truth. Only a statement that is inconsistent to different parties is caught as a lie.
A very important exception is that the focus of this mathematical model is consistency NOT correctness of value x. Therefore, the cryptographic assumption is that members of set T are semi-honest ( they can decide to pass on the value x or not). Dishonesty by any member of set T is undetectable if it is done consistently.
For example if member t₁ intentionally changes the value of x and broadcasts x’ consistently to all other parties, this is not detected as a byzantine fault so t₁ in fact looks honest just like any member of set H.
P2P LAYER (NETWORK) AND SECURITY CONSIDERATIONS
Before we go to the consensus layer and discuss how the BFT algorithm actually works. The naive assumption is that every peer has a full TCP-type connection with the other. Thus, you send a message, wait for an acknowledgement and proceed to the next step. But if this were the case, the entire system would just be too slow and when any node does NOT respond, the entire system is halted.
Instead, messaging is usually batched into 3 phases: Pre-prepare, Prepare and Commit and nodes don’t necessarily need to wait for the other. Also at any time, one node is chosen to lead the process while others follow. This prevents the entire algorithm for ever hanging in the middle because some core-piece went offline.
So it is important to visualise how the network communication is actually happening in this kind of setup. Take a look at the image below.
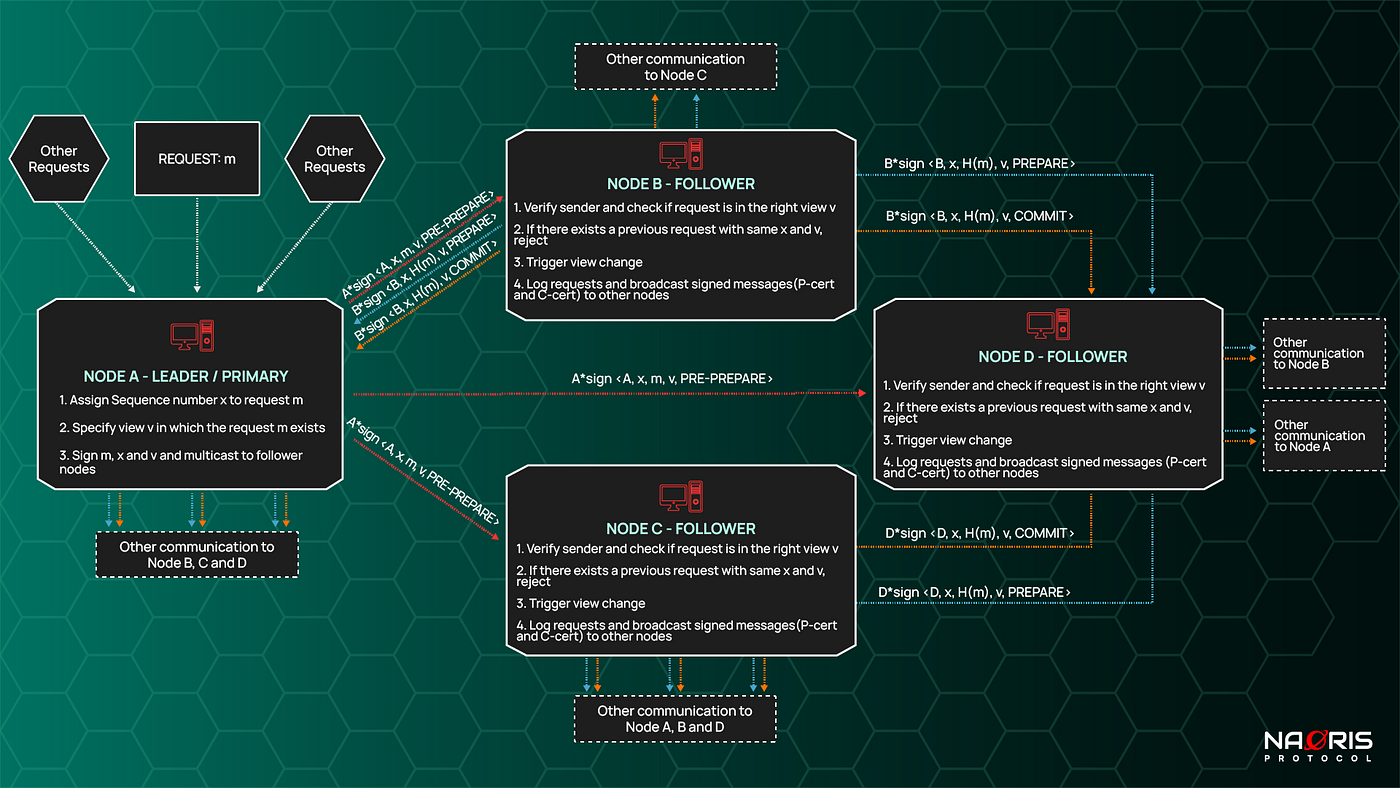
PRE-PREPARE PHASE (red arrows):
- Leader node receives a request message, m, from some client. Leader assigns a sequence number x to the message to ensure that we know which message comes before the other since other messages are also received.
- Leader specifies the view of the message. A view is usually just an integer v. This shows which batch some requests belong to. The view also automatically designates the leader / primary node. Usually through a simple formula like this: i = v mod N (where N is total number of nodes). So let’s say we are in view 401 and there are 4 nodes, 401 mod 4 = 1, this means Node 1 is the leader.
- If the leader does anything malicious like assigning the same sequence number to two different requests in the same view, the follower nodes detect this and trigger a view change; essentially reliving the current leader of his command.
- Leader node A multicasts a cryptographically signed message to other nodes (B,C and D). The message usually contains the node ID: A, the request: m, the sequence number: x, the view: v and a value that shows the current phase the message belongs in: PRE-PREPARE. A*sign<> means node A signs that message with their private key.
PREPARE PHASE (blue arrows)
- The follower / backup nodes verify the authenticity of the message from Leader node (using cryptographic public key). They check if the current view is right. The follower nodes reject malicious requests. Example if the message has the same request number x as a previous message and the same view, this is malicious so it is rejected.
- The follower / backup nodes may also trigger a view change if they determine that the leader node is acting maliciously,
- Finally they log all the correct requests and broadcast it to the other nodes with the PREPARE tag. The content of the message is similar to the one in the previous phase except H(m) is a cryptographic hash of the m.
- Depending on the type of BFT algorithm, they create a Prepare-certificate. This is just an agreed number of correct requests in the prepare phase. So assuming the agreement in the BFT is 2t + 1 (where t is the number of traitor nodes). The follower nodes have to wait to collect 2t + 1 nodes before they create the Prepare-certificate.
- This entire phase ensures that there is a correct ordering of requests within any view.
COMMIT PHASE (orange arrows)
- The Prepare certificates created need to be broadcast to all other nodes. This is done in this phase by all nodes.
- All prepared requests are broadcast with the COMMIT tag.
- An agreed number of committed messages can be collected to form the COMMIT-certificate. The BFT can assume that if say 2t + 1 commit certs are collected, the request is final, take action or reply to the request.
DESIRABLE BFT PROPERTIES and FLP Impossibility
Now that we know how the networked system behaves, it is good to know what are some desirable properties we want from the BFT algorithm.
- Safety / Agreement: No two honest nodes of set H should come to two distinct consensus values. If a BFT behaves this way the consensus is safe. It behaves just like some secure centralised system. So it guarantees that “bad things never happen”.
- Liveness / Termination: Every request to the system must receive a response. So at some point in time, consensus must occur. Eventually the nodes must decide. There shouldn’t be a case where the consensus process falls into an infinite loop and never occurs. So it guarantees that “Something good eventually happens”.
The FLP (Fischer, Lynch, and Paterson) Impossibility basically states that you can’t have both properties in a Byzantine Fault Tolerant system. Bitcoin chooses Liveness over Safety. When it’s hard to come to consensus, the longest chain (with the most PoW wins). Ethereum’s casper is similar but guarantees Safety in certain situations. BFT style algorithms like Tendermint (by Cosmos) chooses Safety over Liveness.
THE 3 CARDINAL MISCONCEPTIONS
Before moving to the consensus protocol, let’s talk about 3 cardinal misconceptions most designers make that seriously impact security of BFT solutions.
- Assuming that faults that will occur will only stop the system or omit some consensus steps. This is wrong because software bugs and malicious attacks change the entire ball game. Attacker can change the entire program running on the local machine. So the fact that the system is still running doesn’t mean it’s not faulty.
- Assumptions of synchrony (message delays and delays between protocol steps). How long do you think it takes for messages to be received and responded to? What exactly is the delay? Assumptions here open a crucial attack vector. 3 main assumptions are made here:
Synchronous → The system has a clear upper time bound for message delays. If message does not arrive in x seconds, consider the node faulty. It is wrong because an attacker can delay certain nodes enough to get enough bad replies and then get a full blown Denial of Service attack. No matter how long this time bound is, it can be broken. Also it slows down the entire system to wait this long
Asynchronous → No upper bound, no delays. You send a message and forget about it. Problem is replication to all nodes is impossible. How do you guarantee that all nodes received the same message you just broadcast? Remember the FLP impossibility
Eventual / Partial Synchrony → There is an upper bound / delay but it is not known to participants (nodes). Most BFT algorithm explore this middle ground. - Assuming the number of dishonest nodes over the lifetime of the entire blockchain solution. This is wrong because there may be more faulty systems given enough time (Remember the lifetime of a blockchain project is very long. Byzantine faults are also hard to detect. Most times detected only when it is too late. Faults are also not independent. Multiple nodes may be controlled by the same adversary or a software bug may be present in multiple nodes
Advice: For the best results, you need to assume that the attacker will compromise and control several nodes; but still play by the rules and behave like an honest node until they are ready to launch a full attack. They will only execute the attack when they have compromised enough nodes and have the numerical majority to breach the consensus protocol. Failure type, synchrony, number of compromised nodes should be carefully considered.
Some partial solutions exist such as: software abstractions which mask diverse implementations. This makes it hard for the attacker to create an attack that is universal against all nodes. There is also proactive recovery. From time to time, check the state of a node and make sure it is honest. Like a stop and search. Also ensure point-to-point authentication so that bad nodes can’t impersonate good nodes.
THE ALGORITHM (CRYPTOGRAPHIC / CONSENSUS PERSPECTIVE)
Now that we looked at the network perspective, let’s look at the cryptographic perspective. This logical abstraction shows the set of steps all nodes must go through before they achieve consensus.
In the 1970s, Lesslie Lamport, Pease and Shostak wrote a paper called “Reaching Agreement in the Presence of Faults”. This paper focused on consistency when different isolated systems interact (interactive consistency).
The algorithm is focused on multiple rounds of private message exchanges that eventually results in all honest nodes belonging to set T (of course of type Ci) computing the same group of values (in a vector). This agreement vector or shared decision is called an Interactive Consistency Vector.
Once this group decision (or Interactive Consistency Vector) is achieved, all components / nodes can use this agreement vector as input to any function to compute any operation knowing that all other honest nodes will follow suit.
High level Understanding of Algorithm (Summary):
- Pre-round (Round 0): Every person / node creates a personal secret.
- First round: Each person / node individually shares their personal secret with ALL the other nodes one-by-one (remember there is no broadcast communication. Only point-to-point). They simply say — “my secret value is …”
- Second round: Each person / node individually shares the values they received from the first round to all the other nodes one-by-one. They simply say — “John told me their secret value is .., Alice told me their value is …, Jane told me their value is .., etc)”
- Next rounds: They continue for as many rounds as necessary. Each round sharing results from the past round. So it ends up like this — “Alice told me, that Jane told her, that John told her, that Samuel told him, that their secret value is ..”. Each round getting more complex than the previous.
- After enough rounds are complete, each node looks at all the communication it has received so far and chooses the most consistent secret values it has received so far for each individual node. This is the so-called Interactive Consistency Vector. If a specific value from a node is inconsistent, a random value say R can be used as substitute soo that even that inconsistency can be made consistent as R.
It turns out that if you do this enough rounds, taking into consideration how many dishonest people / faulty nodes there are, all honest nodes will ALWAYS end up with the exact same interactive consistency vector. This solves the consensus / joint decision problem!
Note that the Pre-prepare, Prepare and commit phases will exist in every round, except round 0 (because it requires no network communications). This is how the network execution is connected to the consensus layer.
WHY DOES THIS WORK?
This is exactly how myths, stories and legends are passed down through the generations. It is always a lot of he said, she said and they said; with every new generation choosing the most consistent story they heard from their mom who heard it from their grandma who heard it 50 years ago from a man who heard it from their great grandfather, … You get the idea :) Now imagine if you had all this communication saved on some hard drive somewhere. You could definitely choose the most consistent story or myth. And that is your Interactive Consistency Vector! There is a more mathematical proof in the original paper. But this is the basic understanding of the mathematical proof you will see if you read the paper.
IMPORTANT: Even in this scenario, if some people in the chain (throughout the generations) consistently tell the wrong story, it is undetectable. This could change the entire myth! This is the exception we spoke about in the previous chapter.
DETAILED ALGORITHM AND EFFICIENCY
To better understand this algorithm, let’s run it for n = 4 nodes (A, B, C and D). We also introduce a fictitious unit of space measurement called a Byzantine Byte (bb). This denotes the number of bits needed to uniquely address n nodes. The point here is that if we can get a quick estimate of the requirements per node, we can easily translate it into real world bits / bytes. For example: mathematically real world bits = log2(n). So 4 nodes need log2(4); at least 2 bits if each node is to have a unique value. (00,01,10,11)

In this pre-round, you need n ( 4 byzantine bytes)
Given n = 4, log2(4) = 2bits per node, therefore real world space requirement = 4 * 2bits = 8bits in pre-round minimum. There are 0 network communications.

Each node has 3 network communications. Total communications = 3 * 4 = 12 = n * (n-1) = 12 communications. Average case is O(n²)
Also there are 4 nodes, and each node transmits information for 3 other different nodes, therefore, each node spends 3bb. Total byzantine bytes spent in entire network at this round= n * (n — 1) = n² — n = ( 16–4) = 12byzantine bytes
For n nodes, you have this requirement: n(n-1). Therefore in terms of space requirements / complexity, average case is also O (n²)
Given this, you can easily calculate that for 4 nodes. The byzantine byte = log2(4) = 2bits Therefore O(n²) = 12 * 2 = 24bits (in the real world)
It means that to perform this algorithm for 1024 nodes, one byzantine byte = log2(1000) = 10bits. Therefore O(n²) = 1000 * 1000 * 10 = 10million bits = 1.25megabytes for just the first round

In terms of network, the same amount of communications take place so O(n²) So n (n -1) = 12 communications
This time the space requirement significantly increases. Each node spends (n-1)² byzantine bytes. Example: Node A spends 9 byzantine bytes
So n nodes spend n * (n-1)² = n * (n-1) * (n -1) = n* (n² - 2n + 1) = n³ - 2n² + n = O(n³)
So in this round for 4 nodes: Each node spends 9 byzantine bytes. 9 * 4 nodes = 36byzantine bytes
Same calculation here n³ -2n² + 1 = 64–32 + 4 = 36 byzantine bytes
HOW MANY ROUNDS ARE ENOUGH?
The number of rounds ends here. If you have 4 people and 1 is dishonest, you can easily conduct a vote amongst the 3 other remaining and come to a consensus. This is NOT true if you have 4 people (n = 4) and the number of dishonest people are 2. In this case, you have only two people left to conduct the vote. Every communication has a 50 / 50 chance of being dishonest.
This problem can’t be solved when this happens.
So the minimum condition under which the problem can be solved is n = 4 and m(dishonest people/ faulty nodes) = 1.
If you generalise this, you realise that the problem is solvable only when n is at least 3 times the number of dishonest parties m. So n = 3m + 1.
A simple way to always know that the algorithm will be solved for a given n is to choose m (maximum number of dishonest nodes)= (n-1/ 3). So if you have n = 100 and you don’t know who is dishonest, you can choose t = (99 / 3) = 33.
This means you assume the maximum of 33 dishonest / faulty nodes and would run the algorithm for m+ 1 rounds (pre-round + m rounds). So 34 rounds.
Important Cryptanalysis point: If ever there were more than 33 dishonest people / faulty nodes, you can’t guarantee trust / safety for any consensus action!
Note that this is the worst case scenario. If you had a way to determine the actual number of faulty parties (m) beforehand, you don’t need to go the full m + 1 rounds. If out of 100 nodes, only 2 are faulty, you only need to go 3rounds! This conserves a lot space and network time.
HOW WOULD SUBSEQUENT ROUNDS PROCEED

This is how round 3 would look like for Node A alone!
In terms of network, each node will still make (n-1) communications. So the total is n(n-1). Still O(n²) = and 12 communications in total.
But for space, each node will consume 27 byzantine bytes (n-1)³
So for n nodes
n * (n-1)³ = n * (n-1) * (n-1) * (n-1) so O(n⁴)
In this example where n = 4
4 * (4 -1) ³ = 108 byzantine bytes
Round m + 1 (last round):
From this we can conclude that in round m + 1, the following will happen. We would still have n * (n -1) communications in that round. So in general we conclude that network communication will be asymptotically quadratic in nature O(n²).
This is very bad because let’s say you have 100 nodes trying to perform BFT, you easily end up with 100² = 10 thousand network communications per round! This is a lot of bandwidth!
In terms of space, we would have n * (n -1)* (n -1) ……(n -1) . There will be (n -1) m + 1 times. For example if m were 33, We would have n * (n -1) ;34 times!
Remember that after all rounds, all nodes will choose the value of the secrets which is most consistent for all nodes. So example: <A:Va, B:Vb, C:Null, D, Vd>. This means throughout the rounds, most people said A’s secret was Va, B’s secret was Vb, C’s secret could not be determined so Null, D’s was Vd. Every node should come to the same vector. This is the Interactive Consistency Vector.
GENERAL FORMULA FOR TIME AND SPACE COMPLEXITY
In general, if you wanted to use this algorithm to solve a consensus problem among n nodes, where m nodes are dishonest, n ≥ m ≥ 0 and n ≥ 3m + 1
Network Communication Requirements
n * (n -1) * (m + 1) = O(n²) since m is ⅓ n
More mathematically
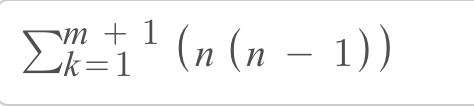
In our example, n = 4, therefore, m = 1, This would be 4 * (4 -1) * (1 + 1) = 4 * 3 * 2 = 24 communications for the 2rounds
Using the summation notation, it would be [ 4 * (4–1) ] + [4 *(4–1) ] if k starts from 1 and executes for 2 rounds. So (4 * 3) + (4 * 3) = 24 communications
Now we run this for 1000 nodes; m = (1000–1) / 3 = 333 faulty parties maximum. Therefore 333 + 1 rounds in total so 334 rounds
So total communications would be
1000 * (1000–1) * (333 + 1) = 1000 * 999 * 334 = 333,666,000 communications!
So about 334million communications across the entire network anytime you want a joint decision or interactive consistency vector.
You can get this same answer by plugging our summation notation formula in an online calculator as follows:
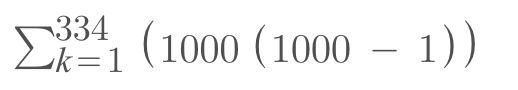
This is a python one-line for this equation for the programming savvy reader:
sum( (n * (n -1)) for _ in range(1,m + 2 )) // m + 2 is used because range function needs + 1
Space Requirements
The space requirement will be as follows for m + 1 rounds and n nodes:
n in pre-round
n * (n -1) in round 1
n * (n -1) * (n -1) = n * (n -1)² in round 2
n * (n -1) *(n -1)*(n -1) = n * (n -1)³ in round 3
…, in round m + 1
n * (n -1) * (n -1) * …(n -1) or n * (n -1)⁽ᵐ ⁺ ¹⁾ in round (m+1)
The answer will be a sum of byzantine bytes across all rounds.
So mathematically, it is a product notation embedded in a summation notation. Space requirement is, therefore, asymptotically exponential. O(nᵏ)
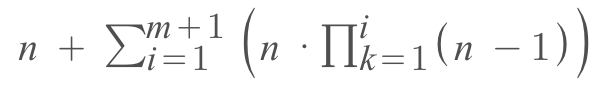
In our example, n = 4, therefore, m = 1, We would have the following calculation:
4 + [4 * (4 -1)] + [4 * (4 -1) (4 -1)] = 4 + 12 + 36 = 52 byzantine bytes
Let’s convert that to real world bits. Each byzantine byte will be log2(n) = log2(4) bits = 2bits
Therefore you require a minimum of 104bits to complete this algorithm for 4 nodes where 1 is dishonest. You can arrive at the same 52byzantine bytes by using the mathematical formula.
Python one-liner
n + sum( (n * math.prod(n — 1 for k in range(1,i+1) ) ) for i in range(1,m + 2 ))
At n = 30 and m = 10, You have 379087267720145400 byzantine bytes = 1895436338600727000bits = 236.929petabytes!
To put this in perspective, it costs roughly $32 for 1TB per month. This means for 236petabytes, it will roughly cost you $7,552,000 or 7.5million US dollars just to get one consensus done. Let’s say you do 1000 transactions in a month, which is very small. This will cost you 7.5billion dollars every month! No one is running such a business just for 30nodes. Somewhere around 20nodes, realising classical BFT becomes impractical!
Something funny happens when you run this equation for n = 100 and m = 33. You need: 7178037704077239094767450478265569893234165481054257787837847488830100 byzantine bytes!!
For 100 nodes, 1 byzantine byte = log2(100) = 7bits, So in the real world:
50246263928540673663372153347858989252639158367379804514864932421810700bits
This is 6.28 * 10⁵⁴ petabytes! just to arrive at one interactive consistency vector! Clearly the space requirement to solve this problem in the practical world is gargantuan!
CONCLUSION
In this episode:
- We understood the classical BFT Algorithm from both the network perspective and cryptographic perspective.
- We covered the FLP impossibility and the 3 cardinal misconceptions when considering security.
- We created two home-brewed equations to show that it is just impractical to attempt to realise this algorithm in practice. Quadratic network bandwidth requirement and exponential space requirement means you can only do this up to about 20 nodes till things become impossibly expensive.
In the next episode, we will cover Practical BFTs. How do we actually try to achieve this classical BFT in real life: solve our network and space complexity issues and also most importantly, and keep the safety property of the consensus protocol?
This has been a lot of Math. Welcome to the intermediate part! Catch you in the next Episode!